Here are the list of the most impotant original google's papers and related open-source projects:
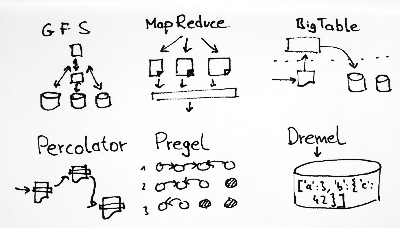
Google File System - 2003 (http://research.google.com/archive/gfs.html)
Short description: distributed file system using commodity machines.
Google File System - 2003 (http://research.google.com/archive/gfs.html)
Short description: distributed file system using commodity machines.
Related Open Source Projects:
MapReduce - 2004 (http://research.google.com/archive/mapreduce.html)
Short description: programming model for distributed processing.
Related Open Source Projects:
Short description: distributed storage system for managing structured data, inspiration for NoSQL databases.
Related Open Source Projects:
Percolator - 2010 (http://research.google.com/pubs/pub36726.html)
Short description: a system for incrementally processing updates to a large data set.
Related Open Source Projects:
Dremel - 2010 (http://research.google.com/pubs/pub36632.html)
Short description: a scalable, interactive ad-hoc query system for analysis of read-only nested data.
Related Open Source Projects:
Pregel - 2010 (http://kowshik.github.com/JPregel/pregel_paper.pdf)
Short description: a system for large-scale graph processing and graph data analysis..
Related Open Source Projects:
FlumeJava - 2010 (http://pages.cs.wisc.edu/~akella/CS838/F12/838-CloudPapers/FlumeJava.pdf)
Short description: a library that makes it easy to develop, test, and run efficient data- parallel pipelines.
Related Open Source Projects:
Tenzing - 2011 (http://research.google.com/pubs/pub37200.html)
Short description: query engine built on top of MapReduce for ad hoc analysis of Google data.
Related Open Source Projects:
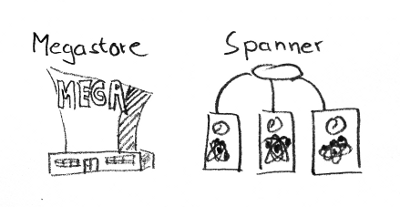
Short description: BigTable + transactions + schema.
Spanner - 2012 (http://research.google.com/archive/spanner.html) and
F1 - 2013 (http://research.google.com/pubs/pub41344.html)
Spanner - 2012 (http://research.google.com/archive/spanner.html) and
F1 - 2013 (http://research.google.com/pubs/pub41344.html)
Short description: hybrid database that combines high availability, the scalability of NoSQL systems like Bigtable, and the consistency and usability of traditional SQL databases.
PowerDrill - 2012 (http://research.google.com/pubs/pub40465.html)
PowerDrill - 2012 (http://research.google.com/pubs/pub40465.html)
Short description: answering ad hoc queries over large datasets in an interactive manner.
Slightly deeper descriptions about the papers, you can find on these links:
http://blog.mikiobraun.de/2013/02/big-data-beyond-map-reduce-googles-papers.html
http://blog.mikiobraun.de/2013/03/more-google-papers-megastore-spanner-voted-commits.html
http://www.rosebt.com/blog/percolator-dremel-and-pregel-alternatives-to-hadoop
A more complete list of big data related projects:
http://blog.andreamostosi.name/big-data/
This is one such interesting and useful article that i have ever read. The way you have structured the content is so realistic and meaningful. Thank you so much for sharing this in here. Keep up this good work and I'm expecting more contents like this from you in future.
ReplyDeleteHadoop Training Chennai | Hadoop Training in Chennai | big data Training in Chennai